Residual Network (ResNet) for Identifying the Digit Represented by a Hand Sign
One of the challenges of training a very deep neural network is the vanishing and exploding gradient types of problems. When we make the network deeper and deeper, it becomes very difficult for it to choose parameters that learn even the identity function. So, the performance downgrades as the network get deeper. This problem can be significantly reduced by using Residual Networks (ResNets). ResNets use skip connections that take the activation from one layer and feed it to another layer much deeper in the network. It reduces the vanishing gradient problem, and the deeper layers can easily learn the identity function, which ensures that the performance will not degrade in deeper layers.
The project is about classifying the digit represented by a hand sign. The dataset consists of 1080 hand images for training and 120 images for validation. 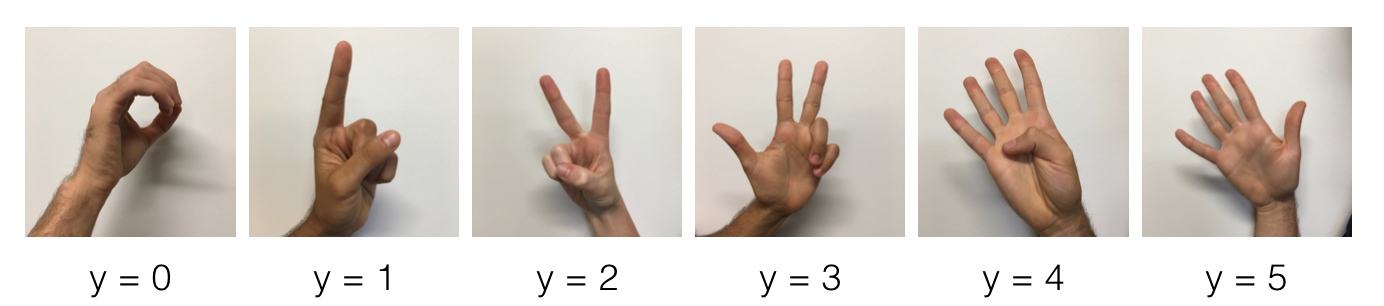
Visual representation of the different classes. Credit: DeepLearning.AI
I created the necessary building blocks to train a ResNet-50 model from scratch. Here is a summary of the model architecture: 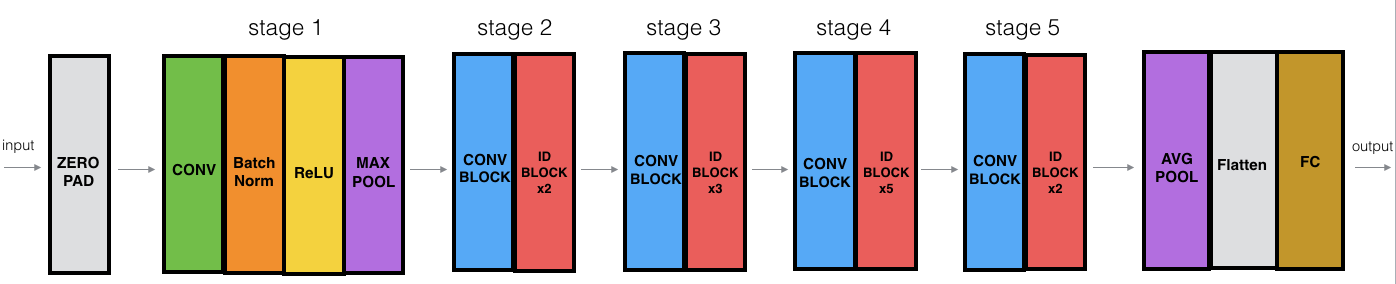
Credit: DeepLearning.AI, Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun - Deep Residual Learning for Image Recognition (2015)
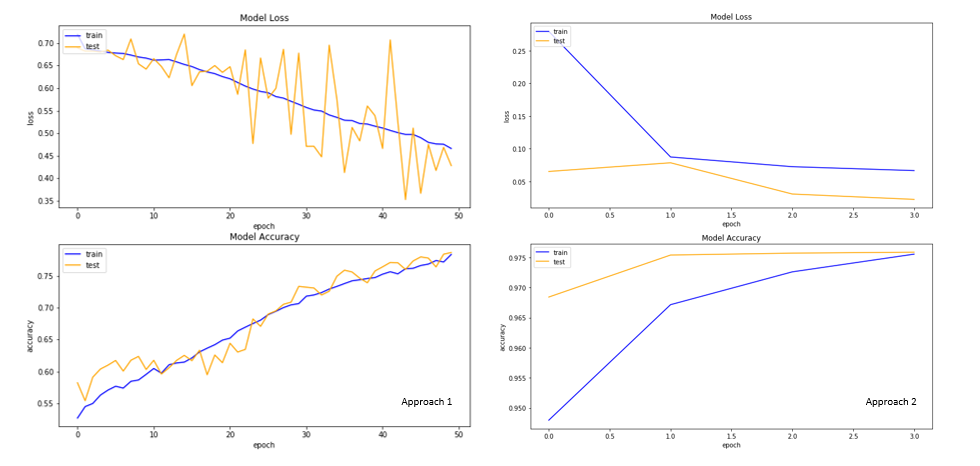
The convolution and identity block has three convolution layers each, with convolution blocks having an additional convolution layer in a shortcut path to make sure the dimensions match up for the later stages. I trained the model for eight epochs and it achieved around 94% validation accuracy! Here is the training history: 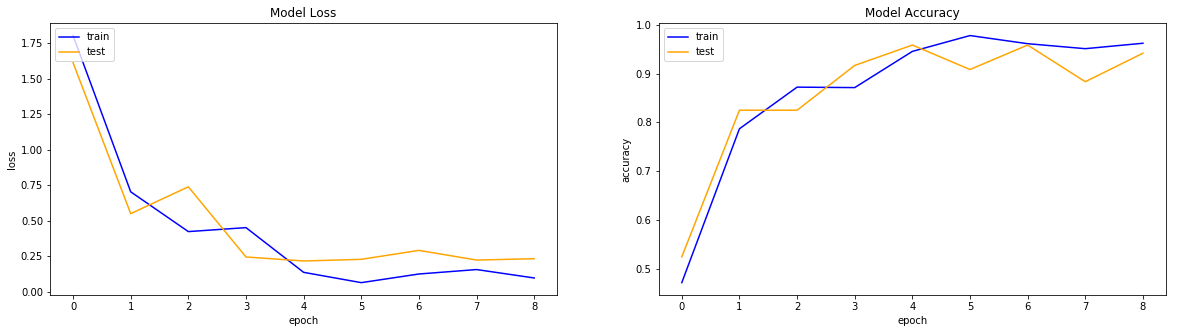
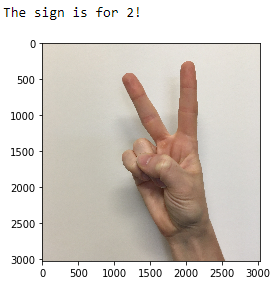
I used the model to classify an image of hand sign!